RAG
🚧 In Progress
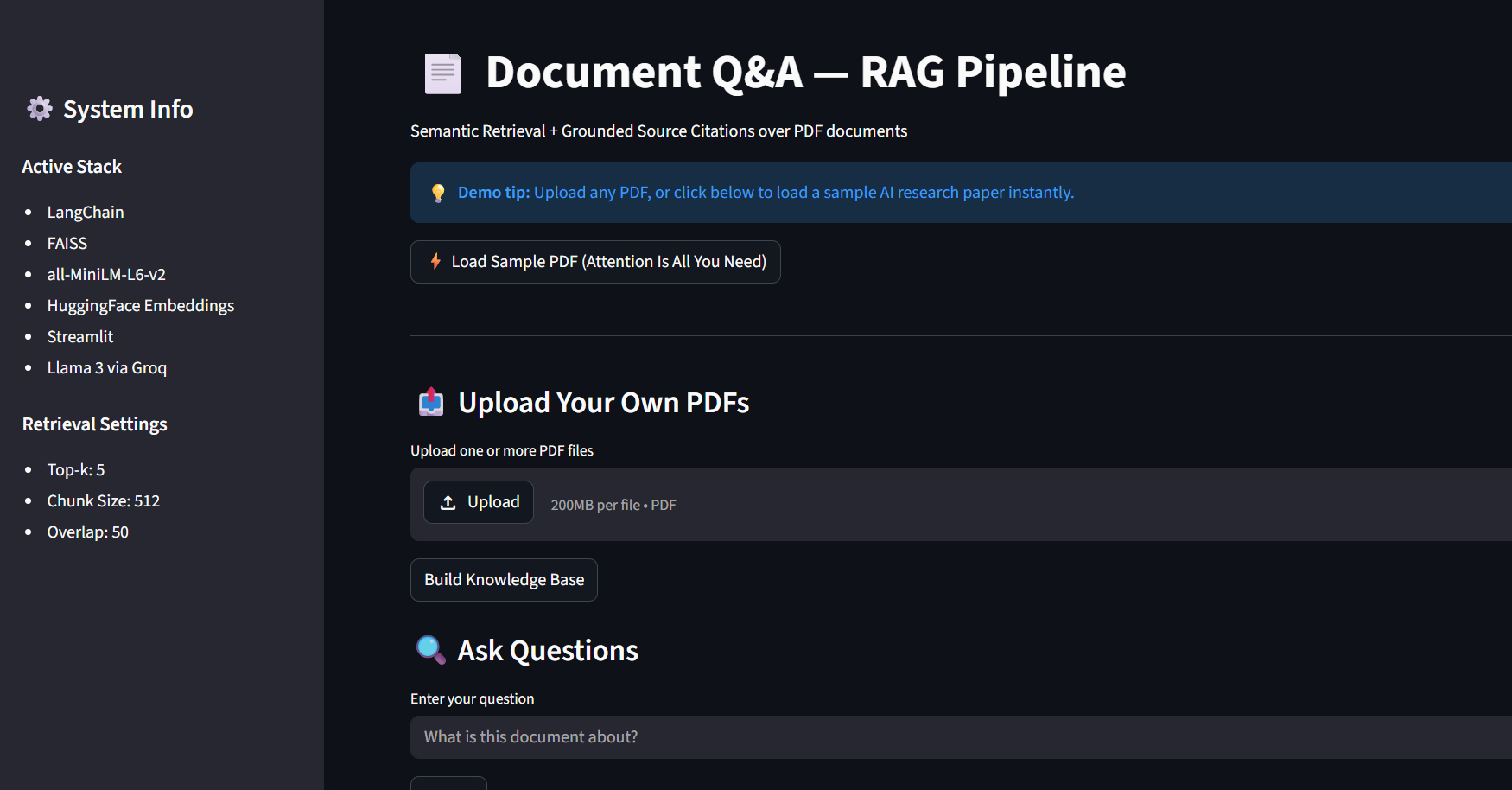
📄 Document Q&A
RAG Pipeline
A production-ready Retrieval-Augmented Generation pipeline for semantic querying across 1K+ PDF documents — FAISS vector search, transformer embeddings, grounded answers with source citations.
⚠ Demo runs on Streamlit Community Cloud with a sample PDF. Full 1K+ doc pipeline runs locally.
BLEU
0.81
DOCS
1K+
LATENCY
1.2s
Live Demo Preview
Model Card
📋 RAG Pipeline — Model Card
Dataset
1K+ PDFs, semantic chunking (512 tokens)
Embeddings
all-MiniLM-L6-v2 via HuggingFace
Vector Store
FAISS (flat index, Top-5 retrieval)
LLM
Llama 3.3 70B via Groq API
Metrics
BLEU 0.81 · Latency 1.2s · 1K+ docs
Baseline
Keyword search BLEU 0.41 → Ours → 0.81
PDF → chunker → embeddings → FAISS → LLM → answer + sources
Progress
✅ Done — Demo Version
Streamlit UI — file uploader, query input, results display
Multi-PDF upload and batch ingestion
Semantic chunking — 512 tokens, 50 overlap
HuggingFace embeddings (all-MiniLM-L6-v2)
FAISS vector store — build, persist, reload
Top-5 similarity retrieval with relevance scores
Context injection into LLM prompt (RAG)
Llama 3.3 70B answer generation via Groq API
Source citations — document name + page number
Query metrics — retrieval time, latency, chunk count
Chunk explorer — inspect retrieved chunks
One-click sample PDF loader (no upload required)
🚧 In Progress
BLEU evaluation framework with labeled Q&A test set
Latency optimization — targeting <1.2s end-to-end
Scale testing across 1K+ document corpus
📋 Planned
Hybrid retrieval — BM25 sparse + FAISS dense fusion
Re-ranking layer — cross-encoder on top-k results
Streaming responses — token-by-token generation
Docker containerization — one-command deployment
MLflow experiment tracking
Stack
LangChain
Orchestration
FAISS
Vector Store
HuggingFace
Embeddings
Groq
LLM API
Streamlit
Frontend
Python 3.10+
Core